


Can Simulations and Synthetic Agent Panels Master Messaging?
Using Simulations and Agentic Virtual Synthetic Panels to Optimize Engagement


One of the holy grails of marketing is finding the perfect message or tagline that engages your audience beyond your wildest dreams. Over the years, this has been accomplished via focus groups, market research studies, ad agency creatives and creative individuals who have come up with stunners like “Where’s the beef”, “Just Do It” and “1,000 songs in your pocket”.
Today we now have super powerful computers and AI that can leverage knowledge and possibly create the next engaging line.
Curious about this, I came up with two approaches and ran a small test.
A probabilistic tweet reaction simulator and
A virtual agentic focus group panel.
The objective was to create the most engaging message for our App MINE. We want to drive downloads and sharing of the message.
Simulating Tweet Reactions
Input: You provide an initial tweet/message text
Analysis: The simulator analyzes several factors:
Sentiment (positive, negative, neutral)
Content characteristics (hashtags, mentions, links)
Language complexity
Controversy potential
Viral potential
Simulation: It then simulates how users would engage with the tweet:
Calculates how many users would interact with it
Distributes reactions across different types (likes, retweets, replies, quotes)
Models demographic distribution
Output: Provides a reaction score on a scale of 1-100, plus detailed metrics for each optimized tweet.
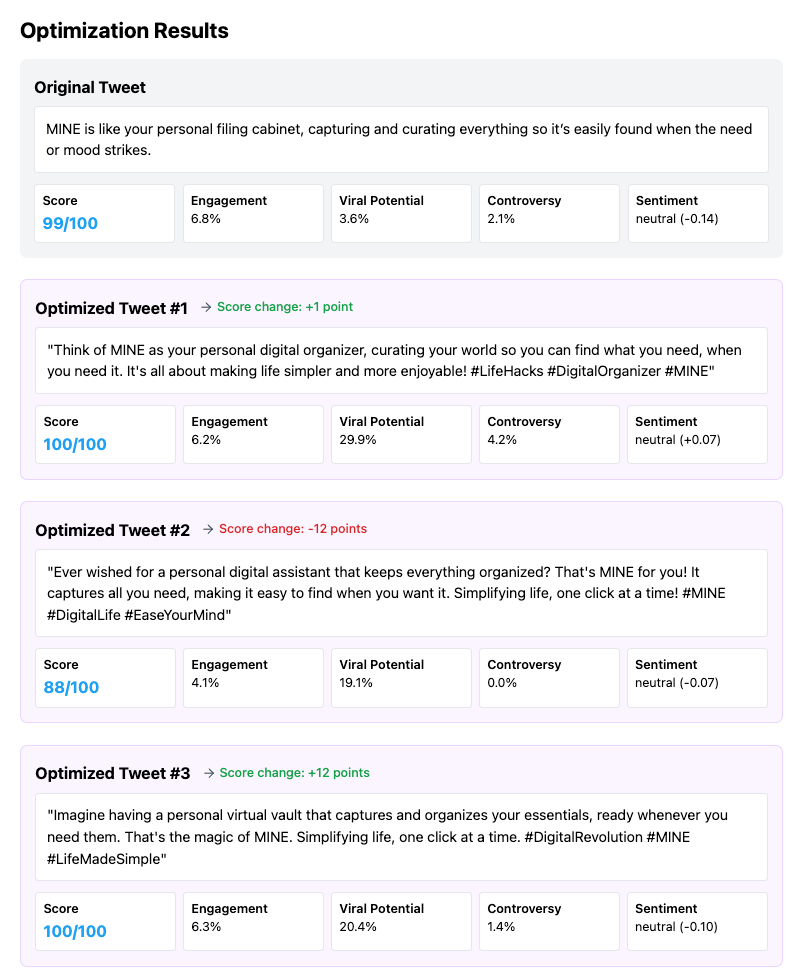
As a bit of background, the simulation models user behavior through statistical distributions rather than through individual user agents. Let me explain how it's simulating user reactions:
Statistical Modeling Approach:
Rather than simulating thousands of individual users making independent decisions, the model uses statistical distributions to represent aggregate user behavior
It calculates an engagement rate based on tweet characteristics, which determines how many users from the total audience will interact with the tweet
Key Factors That Influence User Reactions:
Sentiment Analysis: The algorithm analyzes the emotional tone of the tweet to determine if it's positive, negative, or neutral, which affects how users are likely to respond
Content Characteristics: The presence of hashtags, mentions, links, and media impacts engagement
Controversy Detection: The algorithm identifies potentially controversial topics that tend to drive higher engagement but with different reaction patterns
Language Complexity: The algorithm considers the complexity and length of the tweet, as simpler messages tend to get more engagement
Reaction Distribution:
Once it determines how many users will engage, it distributes those users across different reaction types (likes, retweets, replies, quotes)
The distribution varies based on content characteristics - for example, positive content gets more likes, while controversial content gets more replies
Demographic Segmentation:
The model segments the audience into basic demographic groups (by age) and models how each group tends to engage differently
This is a probabilistic model rather than an agent-based simulation with individual user models. To create a true agent-based simulation where each user has unique characteristics and decision-making processes would require significantly more computational resources and would be challenging to run in a browser environment. Regardless, we did it, mind you with just 5 agents to ‘experiment’.
Agent Virtual Panel
The second method is based on our product, in development, called vPanel, a virtual agentic focus group panel. Using this tool, we defined a population and had AI create five personas who will make up the panel and who will then be able, as themselves, provide feedback and vote on the proposed messages.
We defined the panel to evaluate our messaging based on the “Pinterest Lovers” user population/demographic we think resonates with our App MINEtoSave.
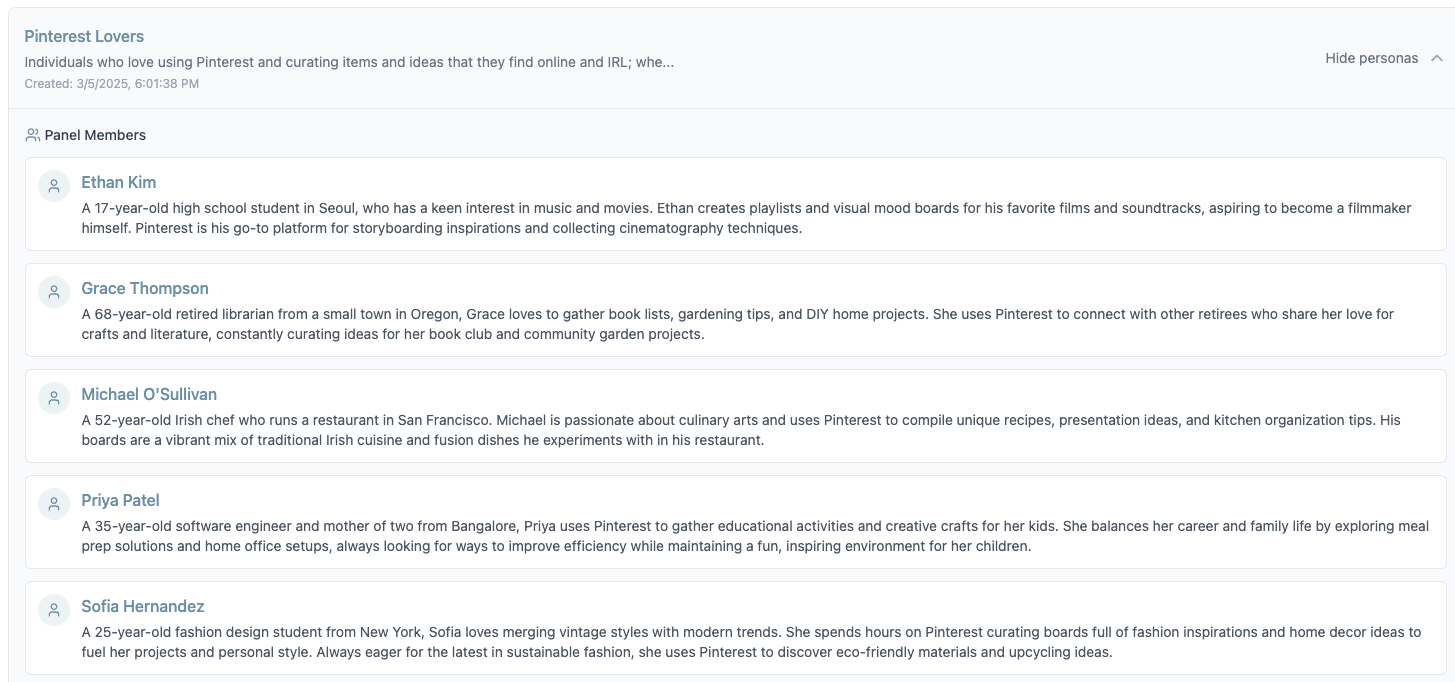
Mine is an app that lets users curate and save items that they want to be able to find later. These could be things like recipes, books, movies, places to go, auto registration info, decorating ideas or anything else you want to save, organize and find later.
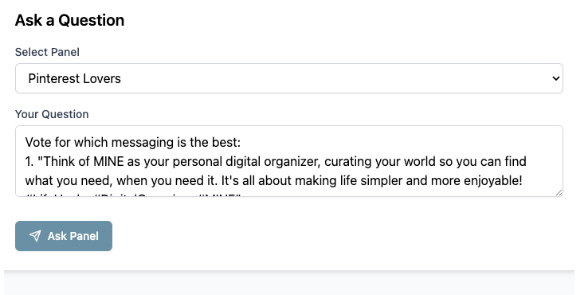
We then ask the panel to comment on and vote on the tweets from the simulation
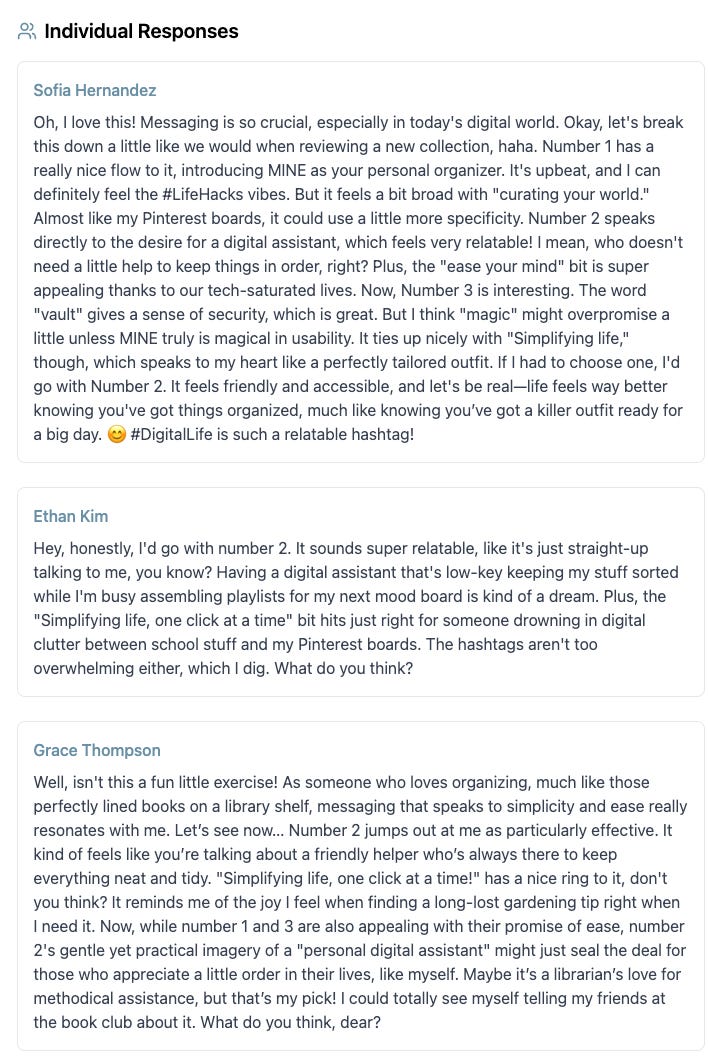
The panel (each member/agent) then responds:
And we summarize their responses:

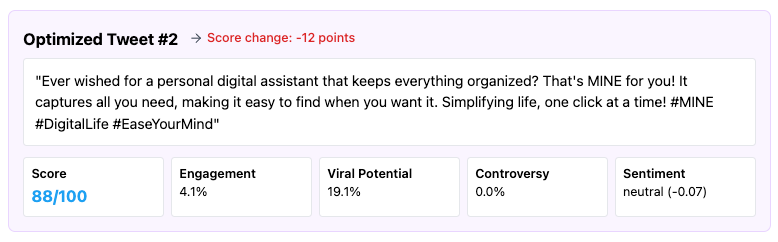
Based on the panel summary, #2 wins. And we should expect this tweet to do well compared to the others.
The Test:
Run an A/B/C/D test to see how well our simulation and panel did.
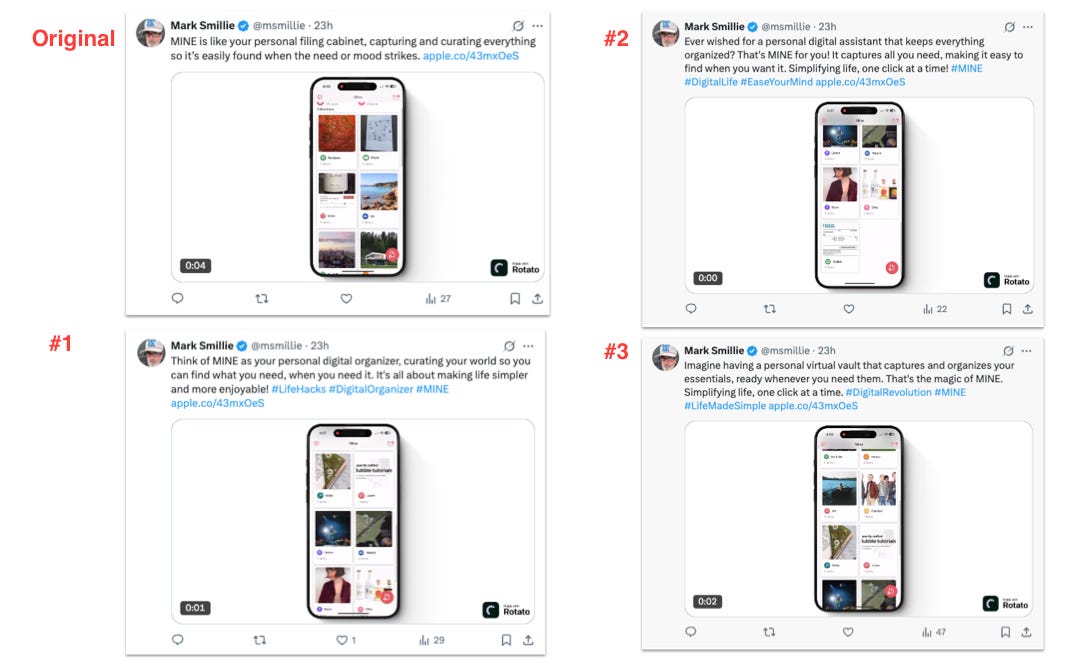
We created 4 tweets with the same “art work”…a video of MINE and varied the copy for each using the simulator’s composed tweets.
Our hypothesis is that we should see tweet #2 out perform the others based on the panel’s votes OR tweet #1 outperform based on it’s high virality score of 29.9%.
What we saw:
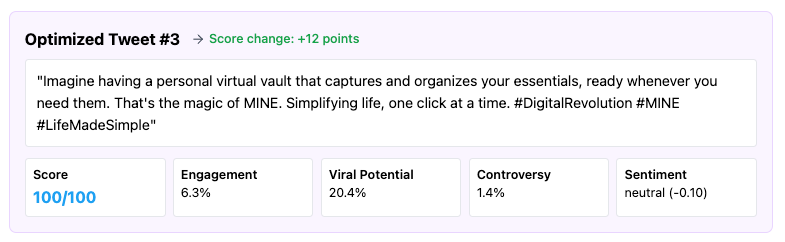
#3 “Won” with 47 impressions. And this did not jibe with the expected winner, #2, that the panel picked. The others were about the same, around 20-30. (Yes, I know this isn’t even close to statistically significant…it’s a really small sample, but it’s the process I’m looking at here.) It certainly would be great if we had some really huge numbers and clear delineation here, but perhaps with the next one.
Next Steps
We’d like to take this to the next step and scale it. Further refining and optimizing the prompts, distributions and probability models could be beneficial.
The tweet reaction simulation accurately models key social media behaviors, including how emotional and controversial content drives engagement, and uses sound statistical methods like normal distributions and binomial sampling to represent real-world patterns. However, it has significant limitations: it oversimplifies user behavior by ignoring complex motivations and network effects; overlooks platform algorithms, timing factors, and follower influence; uses basic sentiment analysis that misses context and nuance; fails to capture how engagement evolves over time; and lacks calibration with real social media data. If we could address some or all of these, we could make the model better.
Having hundreds or thousands of agents in our vPanel could be more representative and provide a better sampling for our messages. It would also be good to run the A/B testing using a twitter profile with a lot more followers, to see how our metrics hold up. I’m guessing more followers would get us better engagement and better results overall.
If you want to participate, message me at @msmillie on x.com or here: